|
Q. How does the English system compare to other kin classification systems in the Murdock data set?
|
|
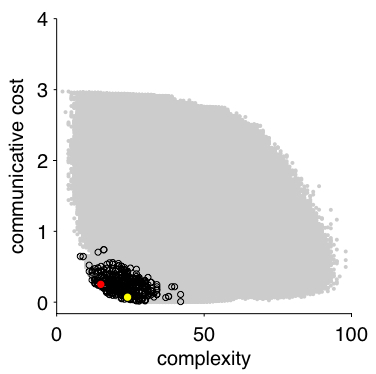
A. The red circle
below shows where English lies within the space of possible systems.
The yellow circle represents the Northern Paiute system shown
in Figure 2 of our paper.
|
|
|
Q. Your paper shows kin classification systems for two languages. What
other kinds of systems are found in the languages of the world?
|
|
A. Brian Schwimmer's
tutorial on kinship terminologies shows some examples.
|
|
Q. If kin classification systems are near-optimal, how can there be so
much variation in these systems across languages?
|
|
A. Our theory allows for variation in at least two ways. First, there
are many different systems that lie along the optimal frontier. For example, English and Northern Paiute have very different kin classification systems, but the plot above shows that English (red circle) and Northern Paiute (yellow circle) both lie near the optimal frontier.
Second, we propose
that attested kin classification systems tend to be near-optimal, but
not necessarily strictly optimal. There are many different systems that lie
along the optimal frontier, and even more systems that lie near the
optimal frontier.
|
|
Q. Is it possible that kin classification systems in the world's languages
are near-optimal because they all descended from a single near-optimal
ancestral system?
|
|
A. This seems unlikely. Although closely related languages often have similar kin
classification systems, there is good evidence that similar systems arose
independently in different parts of the world. For example, the
Omaha
in North America and the
Dani
in New Guinea have similar kin classification
systems even though their languages belong to completely different
families. Cases like this suggest that the same general constraints shape
kin classification in different parts of the world.
|
|
Q. I'm not surprised that kinship systems tend to be simple and
informative: if they weren't, they would be poorly suited to their
function, namely communicating about kin. So is your result just common
sense?
|
|
A. We agree that the principles of simplicity and informativeness seem
intuitive. One way to view our result is that these common sense
principles can explain aspects of kin classification that were previously
explained in terms of principles specific to kinship. An example discussed
in our paper is Greenberg's "ascending vs descending generations"
constraint. Although our paper focuses on kinship, we are optimistic that
the same common sense principles will help to account for cross-linguistic
data in other domains.
|
|
Q. What are some other kinds of categories that vary across languages?
|
|
A. Different languages carve up the space of colors into different
categories. For example, English has 11 basic color terms, including
red, green, yellow, and so on. Dani has just two color
terms: mili refers to lighter colors and mola refers to darker
colors.
Different languages also organize
spatial relationships into different categories. For example, English uses
a single term on to refer to situations where a cup is on a table and a picture is
on a wall. German uses different terms (auf and an) to refer to
these two spatial configurations.
|
|
Q. To what extent does your theory apply to categories other than kinship
categories?
|
|
A. More work is needed to know for sure, but we think that many kinds of
categories are shaped by the factors of simplicity and informativeness. For
example, some earlier work suggests that color naming reflects optimal partitions of color space. In general, our proposal is that categories will
only be passed down from generation to generation if they are simple
enough to be learned and remembered and useful for referring to specific
things.
|
|
Back
to main page
|